
BERT
BERT is a language model published by google. This model can be used for multiple NLP tasks such as NER, Classification, Question and Answer, Sequence Prediction, etc. BERT makes use of Transformer, an attention mechanism that learns contextual relations between words (or sub-words) in a text. The transformer includes two mechanisms, an encoder that read the text input and a decoder that produces a prediction for the task (link). But BERT is a special form of transformer where it uses only the encoder stack of the transformer, not the decoder stack that’s why it is named as Bidirectional Encoder Representations from Transformers (BERT).
One of the biggest problems with the deep neural network-based models is that they require a hell lot of data for training, otherwise they are very prone to overfitting. In NLP there are many tasks and most of the task-specific datasets contain only a few thousand human-labeled data for training.
In the domain of computer vision, people have already solved this problem by developing the pre-trained model on imageNet dataset like vgg16, vgg 19, resNet, etc. These models can be fined tuned on your dataset and you can use their learned feature representation for your task-specific problem.
Similarly in NLP to close this gap Google came up with the idea of BERT, in which the model is pre-trained on a large unannotated text dataset collected from the web. We can easily fine-tune this pre-trained model with the smaller dataset for tasks like NER, Q&A, sequence prediction, classification, etc.
Google claims with BERT model anyone can train their state-of-the-art models in 30 minutes on a single Cloud TPU, or in a few hours using a single GPU. (Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing)
What is different in BERT compared to other models?
BERT is the only first deeply trained bidirectional model and also it is an unsupervised language model. Unlike the other models such as ELMO, ULMFit, GPT, etc. BERT is pre-trained only on plain text corpus collected from Wikipedia data.
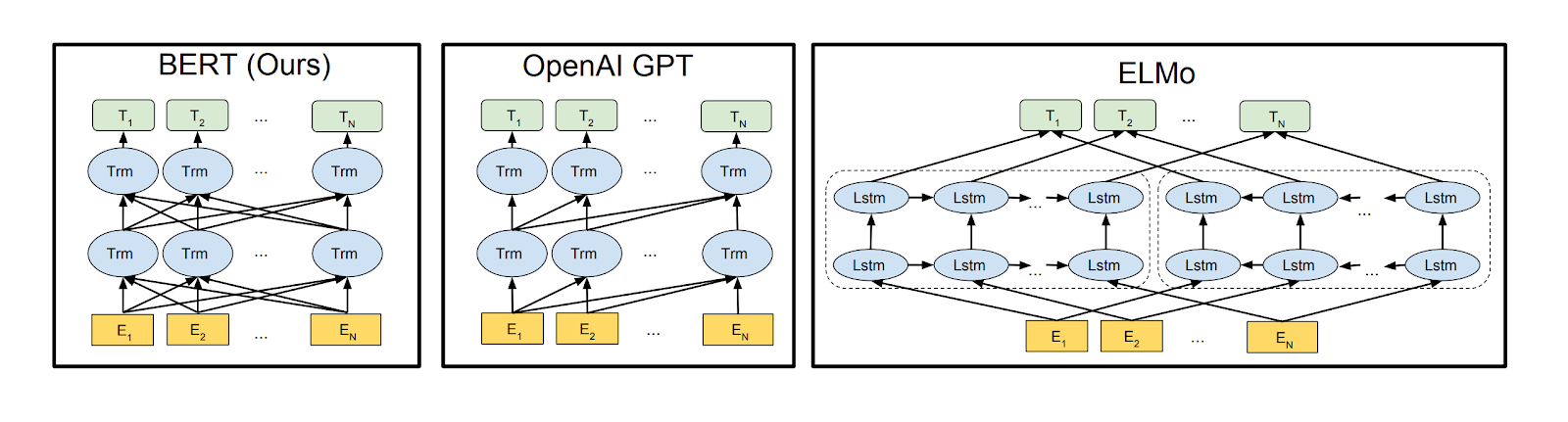
Fig.1 Differences in pre-training model architectures.
As you can see in Fig.1 BERT uses a bidirectional Transformer and OpenAI GPT uses a left-to-right Transformer. ELMo uses the concatenation of independently trained left-to-right and right to left LSTMs to generate features. Also, BERT and OpenAI GPT use a fine-tuning approach, while ELMo is a feature-based approach.
Why BERT approach is better?
In NLP based tasks the representations we use can be either context-free or contextual. Models like word2vec, glove, fasttext, etc. are context-free models in which every word will have the same representation irrespective of the sentence context. For example, the word “apple” will have the same context-free representation in “apple products are great” and in “Eating an apple a day will make you healthy”. But the contextual models will generate a different representation for the word “apple” in both sentences. The contextual model understands the word generally from the words that are before them, in BERT it uses Bi-Directional Encoder which also includes the words that are after the targeted word so that in the end we can generate a better contextual representation for the given word.
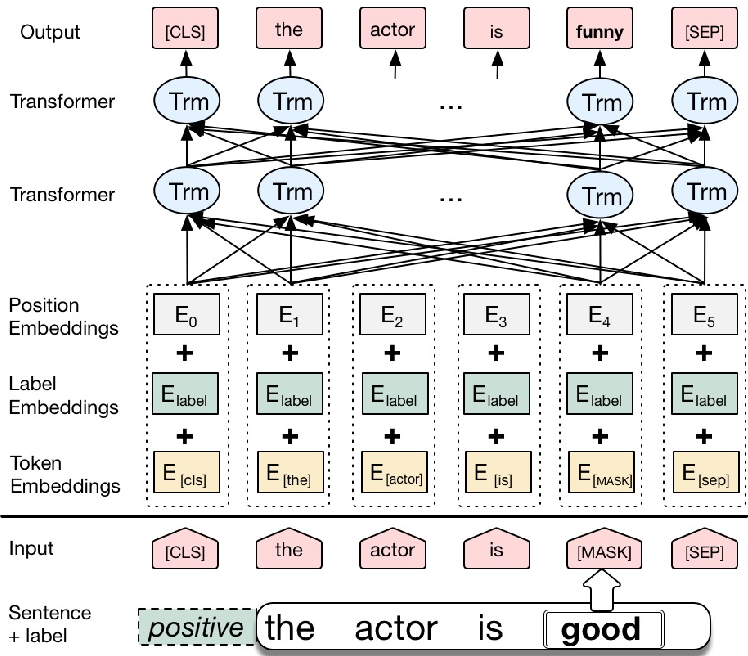
Fig.2 Bert Architecture
Bert I/O
Bert model uses three types of input - token id, sentence id (In which sentence token belongs) and the transformer positional embedding. Along with this, Bert uses some special tokens in its input and output format during its pre-training and fine-tuning task.
- [CLS]: The first token of every sequence. A classification token which is normally used with a softmax layer for classification tasks. For anything else, it can be safely ignored.
- [SEP]: A sequence delimiter token which was used at pre-training for sequence-pair tasks (i.e. Next sentence prediction). Must be used when sequence pair tasks are required. When a single sequence is used it is just appended at the end.
- [MASK]: Token used for masked words. It is used during pre-training. Bert uses MLM (Masked Langauge Model) for training the model and NSP (Next Sentence Prediction).
- [##ing]: These are special tokens, used to represent words like playing. (play + ing). To handle out of vocabulary words.
BERT Input Format
The input embeddings are the sum of the token embeddings, the segmentation embeddings, and the position embeddings.
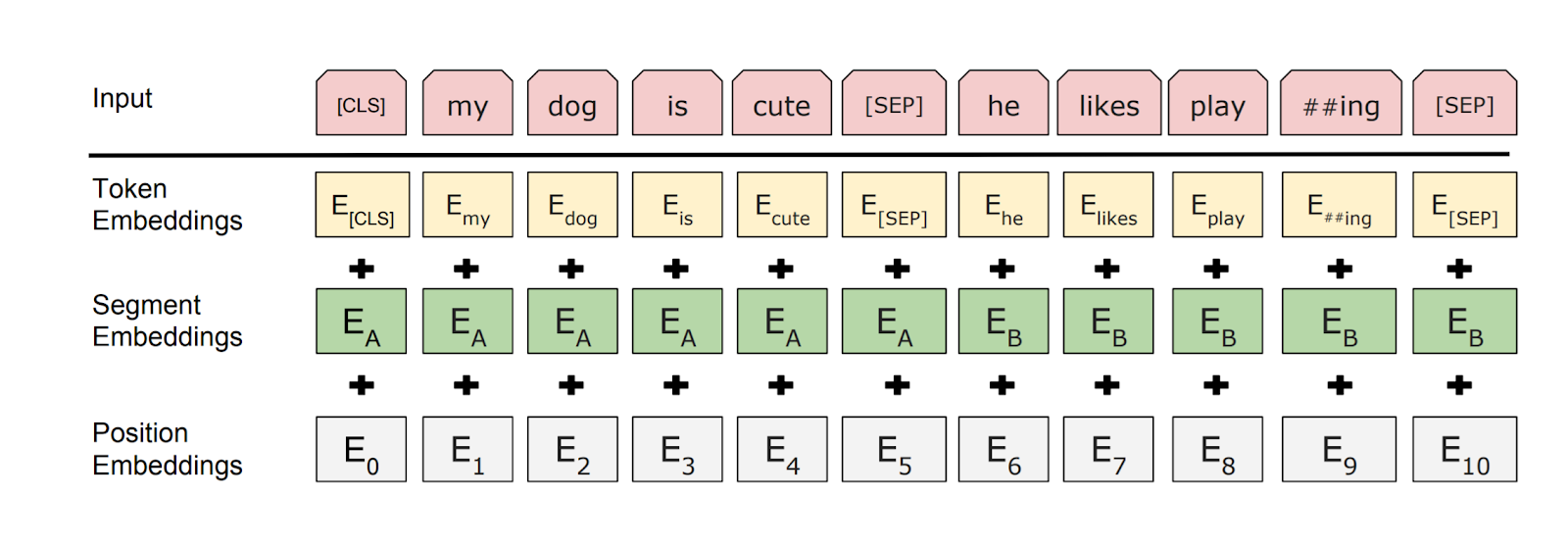
Fig.3 BERT input representation
- Token Embeddings: Vocabulary IDs for each of the tokens.
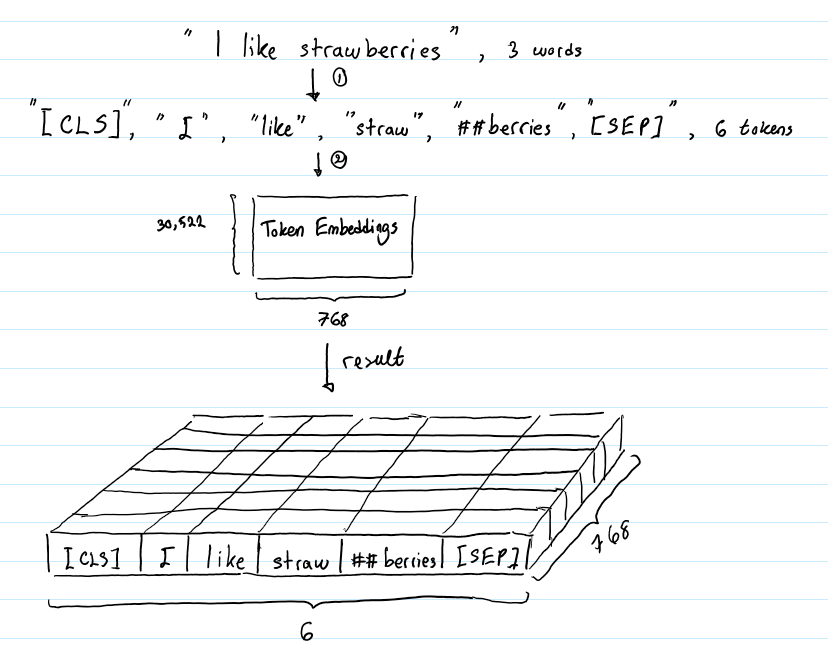
Fig.4 Token Embedding
- Segment Embeddings: Numeric class to distinguish sentences A and B. We will later understand why we are taking two sentences in the pre-training section of BERT.
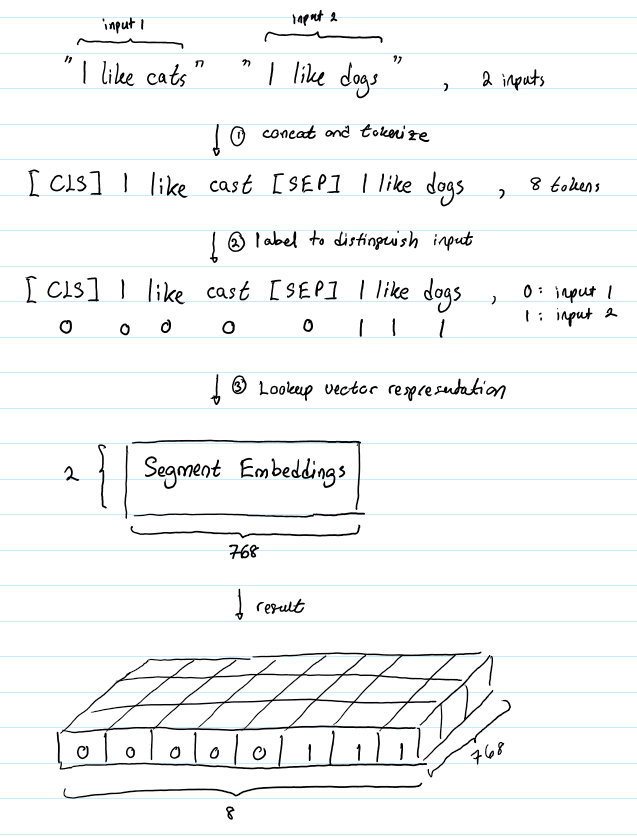
Fig.5 Segment Embedding
- Positional embeddings: Indicate the position of each word in the sequence. This is important in Bert for the transformer to understand the difference between the same word at different position e.g. sentence —> I think I liked recent Marvel movie. In this, we are using the same “I” but they are in a different position and they can have different contextual meanings, so we can specify this part using positional embeddings.
Importance of positional Embeddings
- The architecture of an RNN allows it to implicitly encode sequential information using its hidden state. For example, in Fig.6 RNN that outputs a representation for each word for the sentence “I think therefore I am”.
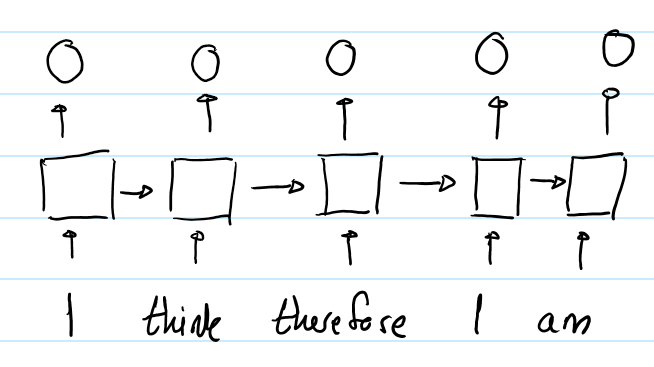
Fig.6 RNN Representation
- In the above sentence, the output representation of both the word “I” will be different because of RNN architecture. In RNN for a given sentence, sequences are fed to the network at different time stamps with changed hidden states. For example, the initial word “I” hidden state is just initialized as compared to the later word “I”. For the 2nd “I” the hidden state will be passed through the previous words “I think, therefore”. which will result in the different output representations. So due to how RNN works the words at different positions will have different output representations.
- But in transformer, input sequences or words are all fed to the self-attention layer at the same timestamp not one by one. So in the sentence “I think therefore I am” for both words “I”, the representation will be the same. So to avoid this case in the input layer along with tokens embedding we also add positional embedding.
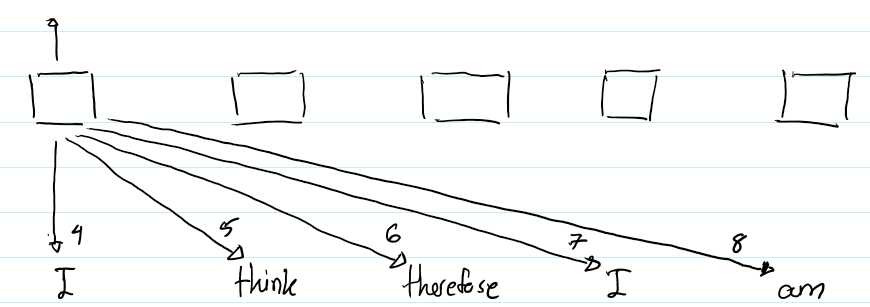
Fig.7
- So in Fig.7 for the word “I” we are keeping the RPR (Relative Position Representation) value of 4, so based on these other words will get the value of 5,6,7 & 8. The number on the arrow represents the RPR value of the respective tokens and these values will be used for computing the attention. So when we are trying to compute the attention between the word “I” and the word “therefore”, it will 6th RPR value, because they are 2 words away from each other.
- The next diagram shows the representation of the 2nd “I” in the same sequence:
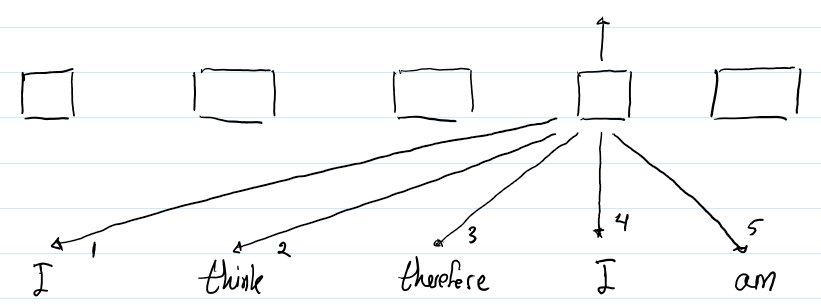
Fig.8
- For the second “I” we will use the same RPR value of 4 to compute output representation. But the RPR value for the words which are to its left and right will change as per the Fig.8. Now when we try to compute the attention between the word “therefore” and “I” it will be different because it’s one word away from the word “I”. So in short what we are trying to preserve using RPR is the relative position between the words and also we have to make it consistent. Read How Self-Attention with Relative Position Representations works for detail information.
- Note this is just the simpler explanation for how positional encoding works in the transformer, in BERT paper they use below equation to maintain the relative information between the tokens. (The Positional Encoding blog).
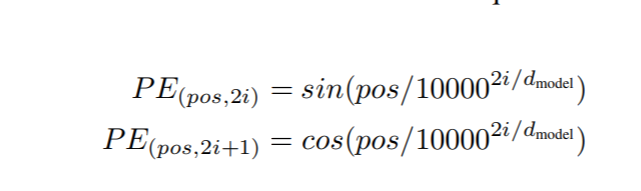
Fig.9 Position Encoding Formula
- In the paper they are using a pre-train positional embedding, which will be added with the all words based on their position in the sequence.
WordPiece embedding
In NLP models, we have input as the sentence “I went to new york last week.” i.e. sequence of words which we tokenize in the form of a list of words [“i”, “went”, “to”, “new”, “york”, “last”, “week”, “.”]. Previous models like word2vec, glove, etc. use tokenizer which tokenizes sentences in the form of a list of words, but all these models have some problems with their way of working. Suppose the model learns the word “old”, “older”, “lower” & “lowest”. Then a word let’s say “oldest” occurs then the model will consider it as an out of vocabulary word, it won’t be able to extract the relationship for the word “oldest” from the learned words or sub-words. Now in this type of scenario using sub-tokens will solve our problem and BPE uses the sub-token method for tokenization. Let’s understand how BPE works.
WordPiece/ BPE Algorithm working
- In order to handle out of vocabulary words, BPE uses word piece to handle or to understand the tokens.
- We count the frequency of each word shown in the corpus. For each word, we append a special stop token “</w>” at the end of the word. We then split the word into characters. Initially, the tokens of the word are all of its characters plus the additional “</w>” token. For example, the tokens for the word “low” are [“l”, “o”, “w”, “</w>”] in order. So after counting all the words in the dataset, we will get a vocabulary for the tokenized word with its corresponding counts.
- Suppose in our dataset, initially, we have only 4 words as you can see in Fig.10 i.e. low, lowest, newer, wider and if a word let’s say ‘Lower’ appeared then it will be considered as OOV (out of vocabulary). To handle this type of scenario in BPE we generally follow four stages of merging to handle unknown tokens.
- In this stage we break down words into its characters, so as you can see in Fig.10 we have our initial vocabulary with the count. We have two words “newer” and “wider” which end with “r” so our new symbol will become r + </w> (</w> represents end symbol) and then we also have “er” in the same two words so we can have a symbol er</w>. Then similarly we have “L” and “O” characters in words “low” and “lowest”. So we can have symbol “LO” and then we have the word “W” added to our word “LO” by which we will have symbol “low” added into our vocabulary.
Vocabulary: {'r</w>': 9, 'er</w>': 9, 'l': 7, 'lo': 7, 'low': 7, . . . . . . . . . . }
- Now a new word “lower” which is not there in the vocabulary can be handled with the above created new vocabulary using word pieces. So to handle it we will break down the word “lower” into low + er (low and er both words are there in the vocabulary) and we can represent the word “lower” low_er</w> as shown in the Fig.10

Fig.10 BPE Working
Encoding and Decoding of the words
- Decoding is extremely simple, you just have to concatenate all the tokens together and you will get the original whole word. For example, if the encoded sequence is [“the</w>”, “high”, “est</w>”, “moun”, “tain</w>”], we immediately know the decoded sequence “the</w> highest</w> mountain</w>”.
- To decode a tokenized list of words into a sentence, we just have to concatenate words which are not ending with the symbol “</w> with the word with “</w>” symbol. For example, if the encoded sequence is [“the</w>”, “high”, “est</w>”, “moun”, “tain</w>”], we just have to concatenate “high” with “est</w> to make “highest” word and then the word “moun” with the word “tain</w>” to make “mountain”. Eventually, in the end, we will get the decoded sentence as ” “the</w> highest</w> mountain</w>”.
- To encode the previous sentence “the highest mountain” we will tokenize them in the list of words with </w> as the end of word symbol after each word like [“the</w>”, “highest</w>”, “mountain</w>”]. So to split the words into sub-tokens we will go through our token list for each word one by one and if the token is present then we will split the word into sub-tokens. For example, we have a list of tokens [“errrr</w>”, “tain</w>”, “moun”, “high”, “est</w>”, “the</w>”, “a</w>”]. Now for each word we will iterate through the token list from the longest token to shortest token. If we found any substring after we have completed the iteration then we will split the word into the sub-tokens. For the word “mountain”, we have tokens [“moun”, “tain</w>”]. For the word “the” we have just “the</w>” and for the word “highest” we will have [“high”, “est</w>”].
- As you can see, the encoding process is computationally very expensive. For each word, we have to search for the list of tokens in the token list. So in actual practice, we can pre-compute our tokenize sentence list in a dictionary and use this dictionary for encoding any sentence.
NOTE: BPE algorithm used in WordPiece is slightly different from the original BPE.
BERT Pre-Training
Bert Model is Pre-Trained using the following two methods
- Masked LM (MLM):
- Assuming the unlabeled sentence is “my dog is hairy”, and during the random masking procedure. We chose the 4th token (which corresponds to hairy):
- 80% of the time: Replace the word with the[MASK]token, e.g. my dog is hairy —–> my dog is [MASK].
- 10% of the time: Replace the word with a random word, e.g. my dog is hairy —–> my dog is apple.
- 10% of the time: Keep the word unchanged, e.g. my dog is hairy ——> my dog is hairy. The purpose of this is to bias the representation towards the actual observed word.
- Since we all know how much prone DL models are to overfitting and if we do not generalize the relationship between the words it will just try to memorize everything. That’s why masking is used with all these three different variations.
- The advantage of this procedure is that the Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced to keep a distributional contextual representation of every input token. Additionally, because random replacement only occurs for 1.5% of all tokens(i.e., 10% of 15%), this does not seem to harm the model’s language understanding capability.
- Assuming the unlabeled sentence is “my dog is hairy”, and during the random masking procedure. We chose the 4th token (which corresponds to hairy):
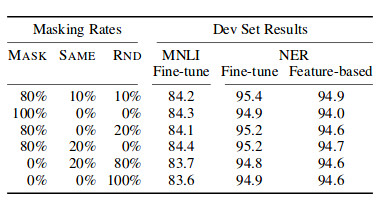
Fig.10 Masking Results
- In the table, MASK means that we replace the target token with the [MASK] symbol for MLM; SAME means that we keep the target token as it is; RND means that we replace the target token with another random token. The numbers in the left part of the table represent the probabilities of the specific strategies used during MLM pre-training (BERT uses 80%, 10%,10%).
NOTE: Read Appendix - A for more details on the importance of masked tokens and also read “Ablation for Different Masking Procedures” in Bert’s published paper for more details on the masking strategies and their results. (link)
- Next Sentence prediction (NSP):
-
Input => [CLS] the man went to [MASK] store [SEP]he bought a gallon [MASK] milk [SEP] Label=IsNext Input => [CLS] the man [MASK] to the store [SEP]penguin [MASK] are flight ##less birds [SEP] Label=NotNext
-
In order to understand the relationship between the sentences, BERT is pre-trained on text corpus where it had to predict whether the given sentence is the next sentence or not. Many tasks in NLP such as Q&A and NLI requires the understanding of the relationship not only between the words but also between the sentences as well. To tackle this type of problems in BERT, when choosing the sentences A and B for each pre-training example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext).
-
Applications
We can fine-tune BERT model on a smaller dataset and can use it for various NLP tasks based on their architecture:
- Classification.
- Name Entity Recognizer (NER).
- Question and Answer (Q&A).
- Feature-Extraction (Word Embedding).
Classification
We can fine-tune BERT model for classification by taking the [CLS] token’s representation from the last output layer and we can compute the class probability with a softmax layer after it.
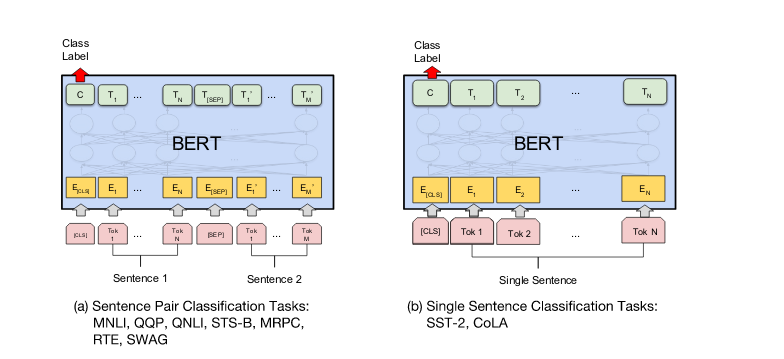
Fig.11 Bert for classification
Name Entity Recognition (NER)
- In NER task we need to assign a tag to each word of the input sequence. It is equivalent to a classification task where the final output representation of the transformer is fed to the classification layer to get a prediction for every token. Because of WordPiece tokenizer, we split words into sub-words so we predict the classification probabilities only for the first token of a word.
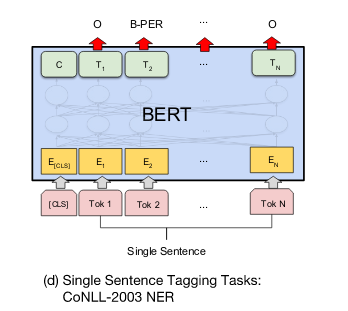
Fig.11 Bert for NER
Question and Answer (Q&A)
- Question answering is a prediction task. Given a question and a context paragraph, the model predicts a start and an end token from the paragraph that most likely answers the question.

Fig.12 Bert for Q&A
- Just like sentence pair tasks, the question becomes the first sentence and paragraph the second sentence in the input sequence. There are only two new parameters learned during fine-tuning a “start” vector and an “end” vector with a size equal to the hidden shape size. The same applies to the end token.
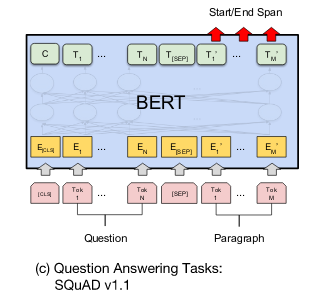
Fig.13 Bert for Q&A
Feature-Extraction (Word Embeddings)
- We can use BERT for feature-extraction as well and use other models on the extracted feature. But just taking the last layers output representation of each word won’t give good results, to get better results we need to combine the output of certain layers. The BERT authors recommend not to use directly the [CLS] token embedding to get the representation of the whole sentence, it works well for the classification task only. The authors tested this by feeding different vector combinations from the different layers as an input to a BILSTM model which was used on an NER task and they computed the F1 score for the evaluation.
- So the concatenation of the last 4 layers on the NER task along with some other task gave the best results. But, it is recommended to test different combinations for a different types of problems.
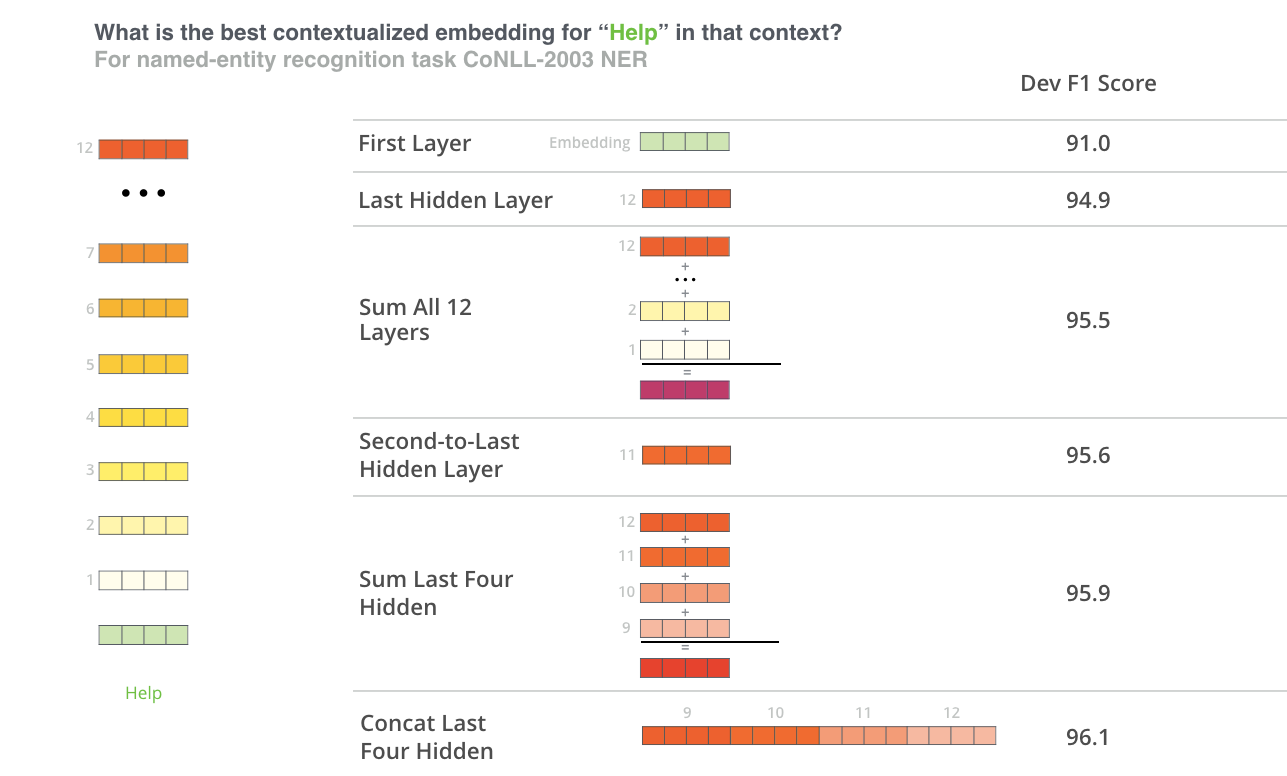
Fig.14 contextualize words embedding
Refernces
- Google AI Blog
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Attention Is All You Need
- BERT Architecture
- How the Embedding Layers in BERT Were Implemented
- How Self-Attention with Relative Position Representations works
- Byte Pair Encoding
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)