
Deep Learning Based Large Scale Recommendation System part 1 (Candidate Generation)
Improving the quality of recommendations is one of the major focus of recommendations systems used worldwide. Capturing the user behavior in better way is one of the directions. Even with the best of the algorithm, we can’t capture user’s entire behavior and also this behavior changes over time. Till now, there are models with very limited understanding in specific domains like machine learning, deep learning, NLP, vision, etc. Evidence from just one or two methods is not sufficient to continuously evolve the system; there is requirement of systematic ways to combine signals from different methods/models.
While combining the signals from different models, context is an important factor to be taken into account. Different methods/models generally work in isolation and don’t have much information on basis of output from other models. In recommendation systems, the output from different methods is generally an ordered list of items to recommend. It is challenging to prepare a global recommendations list using different recommendation lists.
So I will explain one of the YouTube’s paper and explain how they provide recommendations to such large scale. If you want to dig more deeper you can read the Deep Neural Networks for YouTube Recommendations research paper.
Followings are some of the biggest challenges faced by internet based company in recommendation system:
- Scale
- Freshness
- Noise
Noise could be in any form e.g., unstructured metadata, user’s external historical behavior that are hard to detect. In-order to generate the engaging and personalized recommendations, we can divide our problem in two separate problems:
1. Candidate Generation
2. Ranking Candidates
Note: Candidates mean items which are more likely to be recommended to a given user by the recommendation methods.
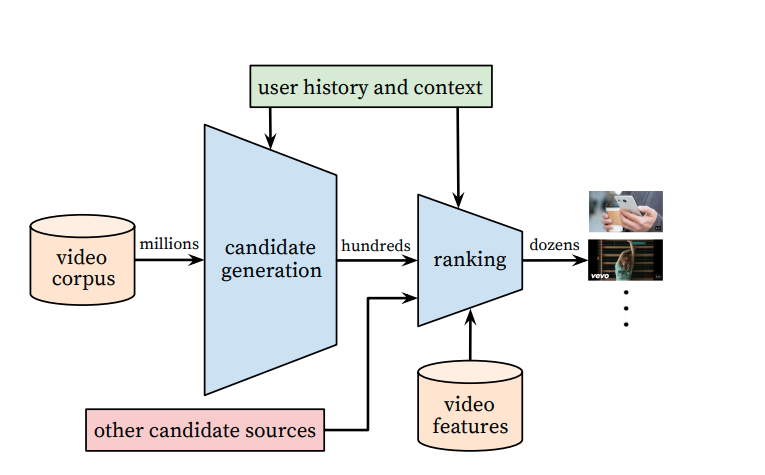
Fig.1 Recommendation System
Candidate Generation:
Candidate generation is the process of generating candidate items from various algorithms. The purpose is to get a wide variety of items, which user may like. Thus, providing an opportunity to present a diverse set of personalized content to user.
Ranking Candidates:
We compute score for all the candidates generated by various methods using any model. This scoring model can be a statistical model, predictive model, neural network-based model, etc. All we want from this model is to generate a score for each candidate so that we can re-arrange their order.
Remember from our large content corpus using candidate generation method we are only selecting the most likely content for user (hundreds of items out of N) and using scoring models we can sort these content and select only top K items that user is most likely to enjoy.
We will limit this blog only till the candidate generation part, the ranking model part will be explored in part-2 of this blog. Let’s now move further and define the problem statement for our candidate generation model. Here our objective is to extract the personalized engaging content for each user.
Candidate Generation Problem formulation:
Here, we’ll try to predict the broad level personalized candidate for each user with high precision and in ranking phase we will focus on high recall. By this way first we are aggregating the contents that would be engaging for a particular users and then we are re-arranging and selecting the top K contents on which user will spend his/her more time.
Purpose is to extract top 100 out of 50k or 60k candidates which are most likely to be watched by user, that is why we are focusing on higher precision. Mean Average Precision (MAP) can be used as one of the Evaluation Metric here.
So the ML/DL based problem formulation for Candidate generation stage can be considered as an extreme multiclass classification problem in which the probabilities of each content will be predicted and the content with the highest probability will be considered as the next watched content. So, during model training we will train the model by letting it predict the next possible watch content by the user and learn the required information out of it.
YouTube Model architecture:
Our main objective is to learn the user-context and each content’s embedding. The Model architecture is a simple Deep neural network with following layer.
Input:
In fig 1. Watch vector represents user history behavior and other vectors such as search vector, geographic embeddings, example age, gender helps to capture the context of user. In this we can add more features like Tod, dow, dtype, etc. to better represent the context of user.
Hidden Layers:
Neural network of depth 4 is used 2048 --> 1024 ---> 512 ---> 256 all with ReLU activation function. This last layer of ReLU output represents the user-context vector.
SoftMax Layer:
This last SoftMax layer will output the probability for each class i.e. content out of which the top content will be selected as the next content.
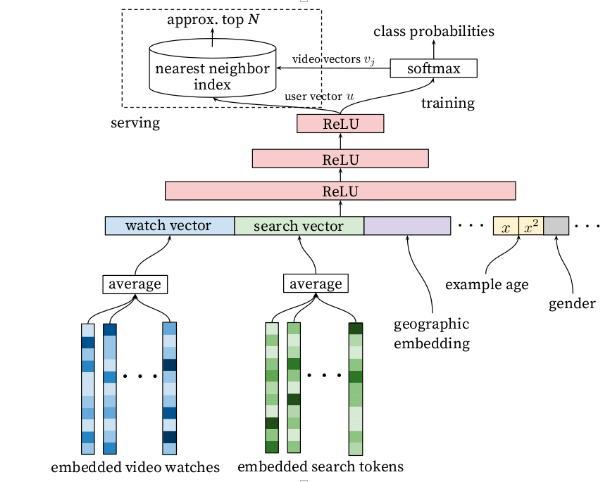
Fig.2 Candidate Generation Model Architecture
Input Features:
- Last 50 watched content: One hot encoded vector of size equals to num of content considered for training e.g., 1 million in case of YouTube.
- Last 50 search query: One hot encoded vector of size equals to total number of unique words found in training.
- Demographic information (Location): Location information of user to push more regional or suitable content to user. This will be one hot vectors of size equals to number of locations that are available to us in the form of circle. This feature will also help us to generate candidates for new users.
- Contents Age: Content’s freshness relative to the training time, idea is to promote fresh content in case of short videos. Single valued feature between 0 and 1.
- DEVICE_TYPE: Device through which user consume the content information. One hot vector of may be 5 or 7 length depending upon the number of unique device type we have.
- LANGUAGE: Preferred language of user, again one hot vector.
- USER AGE: Age information of user to push related content such as 18+ content. Single valued feature.
- Logged in state: User is whether logged in or not. (binary feature)
- User Gender: One hot vector based upon number of unique gender information.
- Other features describing user’s behavior.
- Other features describing item’s behavior.
Training Phase:
For training the model we will take each user last k watched item and k searched query, we are limiting the watched content and search query to last k elements only to avoid the bias of extreme users i.e., if a user has watched and searched more than k then also, we will only take his/her last k queries only, by doing this we will make our model more robust and not to be biased towards highly active users who have watched more contents. (This adds more fairness to the model architecture)
One thing to take care is to provide search token in random order, otherwise the recommendation generated for the user will be biased towards last searched query’s search result content. e.g. If user’s last searched movie was ‘Bahubali’ then the candidate recommended by model will mostly be biased towards ‘Bahubali’ movie.
The main idea in training is to predict the users next watched content at time t. So, if we are taking the content watched by user at time t as ground truth then the last k watched content from time t-1 will act as the input to the model.
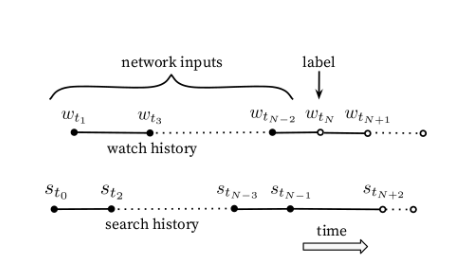
Fig.3 Predicting Future Watch
In order to create watch vector and search vector we will do the averaging of last k vectors as shown in fig.1 experimentally averaging has performed better over sum, component wise max, etc. Approaches as per the paper.
The last ReLU layer’s output will be our user-context representation of N-dimension and this same user vectors will be used during the serving time as well, more on this later.
Now let’s understand the final layers architecture of the model and how this user-context vector will be extracted and used.
SoftMax layer Architecture:
After training is done, we can extract vector U and V from the trainable params. This is like the traditional matrix factorization approach in which we get U (user factor 256 dim) and V (item factors 256 dim). Here we have more contextualized user and item factor from the deep learning model.
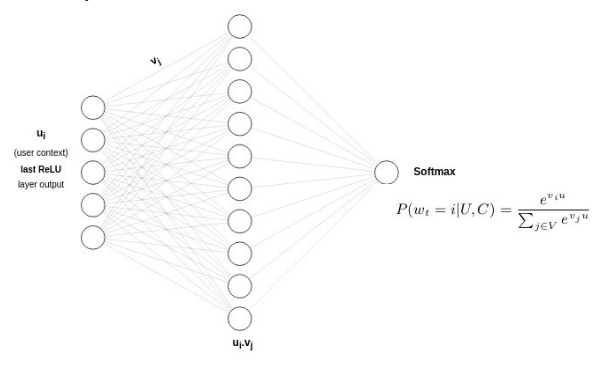
Fig.4 Softmax Layer
Serving Phase:
At serving time to make very quick predictions in milliseconds, we must compute the top N candidates quickly using any linear time based Nearest Neighbor algorithms. These top N candidates will be provided as an input to the ranking model.
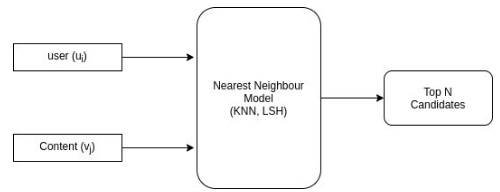
Fig.5 Serving Phase