
Deep Learning Based Large Scale Recommendation System part 2 (Ranking Candidates)
In this post we’ll discuss in detail about the ranking candidates problem and how can we optimally rank these candidates. So that we can provide much better personalized recommendation to our each user.
To solve this ranking problem, we use the concept of “Learn to rank” method which can generate scores for a given pool of item based on the objective we are trying to achieve such as maximizing user watch time. We need an appropriate ranking model which can learn & understand the wide variety of information to generate the optimal ranking for our individual user.
Fig.1 Recommendation system overview
Note: Scoring and ranking are representing ranking candidates here.
In the previous blog we discussed about the candidate generation method in detail, If you have not read it, I will highly recommend you guys to first read that blog so that you can better understand the big picture. Following is the short explanation for it.
Candidate Generation:
Candidate generation is the process of generating candidate items from various algorithms. The purpose is to get a wide variety of items, which user may like. Thus, providing an opportunity to present a diverse set of items to user. In Candidate generation, we can generate list of candidates from various Candidate generation methods from both contents based filtering and collaborative filtering methods.

Fig.2 Candidates generation methods
Let’s start by first understanding why we need ranking model in the first place and then later we’ll formulate the problem statement for our ranking candidate problem.
Why Do we need Ranking/Scoring models why not to use scores generated by candidate methods?
Candidate generation part comes mostly from computing similarity based on user factors or item factors, If we are using matrix factorization based collaborative model or even non-linear DL based generalized model. We can use their similarity score as a ranking parameter. But we should avoid doing this, because of the following reasons:
* The scores of these candidate generators might not be comparable. Let’s say the scale in which collaborative filtering models is generating score might not be comparable with the content-based model score.
* With a smaller pool of candidates, the system can afford to use more features and a more complex model that may better capture context. For example, in ALS candidate generation does not consider the entire user-experience part while generating the recommendation, it only optimizes the user-item rating.
In-order to maintain the better user-engagement we can add fairness, diversity and freshness part to the candidate list by applying another layer of these parameters on the candidate list through ranking model by providing relevant features.
Because the ranking model is only using the list of candidates generated by various methods Suppose if a user only watches certain type of content it will only recommend movies only related to his/her preference and hence it will impact the user’s overall experience in the longer term. Along with his preferences we need to provide certain content which he/she is most likely to explore by promoting diverse content from the list of generated recommendations which users will enjoy and at the same time we are also as a system learning new behavior about the users which will help us in future for generating better personalized recommendation. Below is the Netflix result of ranking model:
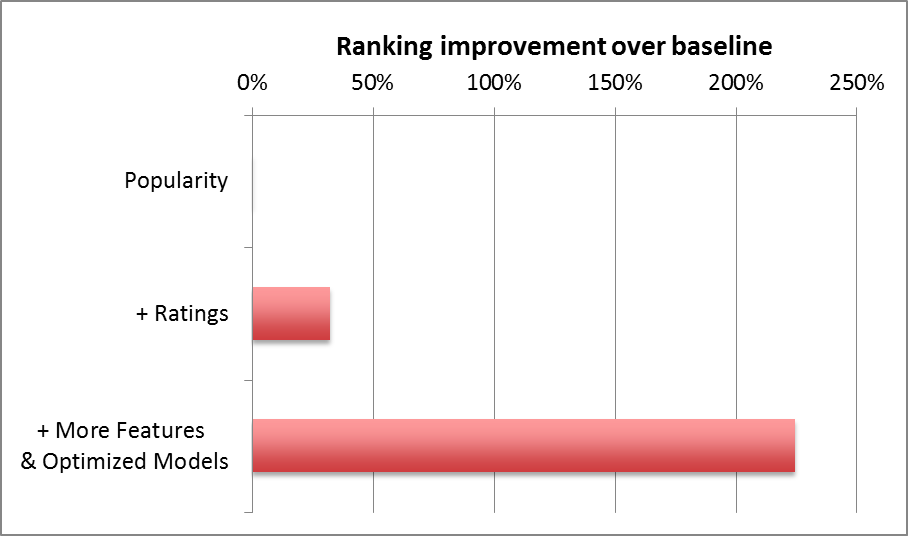
Fig.3 Netflix Ranking model Result comparison
As we can see above just by adding more and better feature how the ranking model and user consumption was improved. We all know the idea of garbage in garbage out and features act as an input to models. So, if we want to design a model which better support our system we have to think heavily on type of features we should consider as an input for our model. But at the same time type of model we’ll be using is also equally important, suppose we added all the required features but if our model is not capable of comprehending those features then these features become useless. So now let’s define our problem statement and decide what all features will be useful to the model and finally we’ll discuss about the model architecture.
Ranking Candidates:
We need to define a Method which can generate scores for a given pool of item based on the objective we are trying to achieve such as maximizing user watch time. We need an appropriate ranking model which can learn & understand the wide variety of information to generate the optimal ranking for our individual user. First question we must answer before selecting any model for our scoring method is what should be our objective function? We can define the objective function which: 1. Maximize number of watched content (Click Rate). 2. Maximize user watch time. 3. Maximize user session watch time.
As we all know in ML & DL domain, model can happily learn the objective we provide, but that’s where we’ve to be very careful of what we want, and this same thing applies to recommendation domain as well. The type of scoring function can heavily impact our ranking of item and recommendation quality. Following are various objective functions scenario we must be aware of.
For Example:
Maximize Click Rate: If the scoring function optimizes for clicks, the systems may recommend click-bait videos. This scoring function generates clicks but does not make a good user experience. User interest may quickly fade.
Maximize Watch Time: If the scoring function optimizes for watch time, the system might recommend very long videos, which might lead to a poor user experience. Note that multiple short watches can be just as good as one long watch.
Increase Diversity and Maximize Session Watch Time: Recommend shorter videos, but ones that are more likely to keep the user engaged.
Based on our problem definition we should be very clear about the type of objective function we wish to choose. For example, in case of news apps or YouTube contents freshness and duration play a quite vital role and hence the maximizing session watch time objective function or click rate objective function will work and for product like amazon prime and Netflix Maximizing the user’s watch time make more sense.
Based on model evaluation results, we can pick the best performing model easily, but first question that we need to address is, how should we decide features?
Input Features:
One of the important things that needs to be provided as an input feature is the temporal sequence of user behavior which will help to predict the expected watch time of the candidate much better based on the current context. e.g. In case of movies and TV shows, we can have features like time spent by user on the genres, star cast of the current content. Also, in case of news time spent by user on newspaper’s news i.e., economic times, The Hindu, etc. Will help in better ranking the candidates. All these features can be extracted from the item-profiling and user-profiling. Also, candidate generation sources and their score could also be included in the input feature. Most importantly the frequency of the past watched video can be provided for introducing “churn” in recommendation, if a user was recently recommended a video but did not watch it then the model will naturally demote this content on the next URL hit.
So, the basic idea in ranking model is not to use directly item’s feature in isolation or user’s feature in isolation. We need to combine both features, so that we can capture more personalized behavior as well. Because, we’ve to remember what we are trying to achieve with scoring method, our goal was to rank item as per the user consumption in an optimal way. In candidate generation we’re taking only users features mostly, but since we have the top N candidate and our aim is to optimize the ranking, so we will be considering both users and contents features here.
Following are the user Features which might be useful in defining user pattern to the model:
- TOD: Time of the day information about the users. Normalized vector with dimension equals to 24.
- DOW: Day of the weak consumption information of users. Normalized vector with dimension equals to 7.
- DEVICE_TYPE: Device through which user consume the content information. Normalized vector of user’s device type info. (dim = num of unique device type)
- LOCATION: Location information of to push more regional or suitable content to user.
- LANGUAGE: Preferred language of user. One hot vector of size equals to number of unique languages.
- USER AGE: Age information of user to push related content such as 18+ content also will be helpful for new user. Single valued feature.
- Features from USER_PROFILING
Following are the Content Features which might be useful in defining content pattern to the model:
- GENRE: Genre of the content in case of Movies or TV show type of content. One hot vector.
- CAST: List of cast involvement in the content. One hot vector.
- LANGUAGE: Content’s language information. One hot vector.
- CONTENT_POPULARITY: Information about the content’s popularity. Single valued feature between 0 and 1.
- TOD: Time of the day consumption pattern of content. Normalized vector with dimension equals to 24.
- DOW: Day of the week consumption pattern of the content. Normalized vector with dimension equals to 7.
- DEVICE_TYPE: Content consumption patter as per device type. Normalized vector with dimension equals to num of unique device type.
- VIDEO_AGE: Information regarding content’s freshness. Single valued feature between 0 and 1.
Above type of features can help a lot in deciding the preference of the item for a given user. Because for e.g. let’s say if we have a location information of a user and we have an items language (regional) feature then our model will learn these patterns and will give higher score to the regional language as per the model training and user consumption. This type of feature can help a lot in providing the regional content to user.
So, this was pretty much about features engineering part, we can think of ranking model as generating a score for each candidate, so that we can rank them in order of their scores. Model can be trained on predicting the expected watch time of the user given a candidate as input. Since after generating candidates we want to rank those candidates higher on which user will spend more time on compared to other candidates. Lets define the model structure.
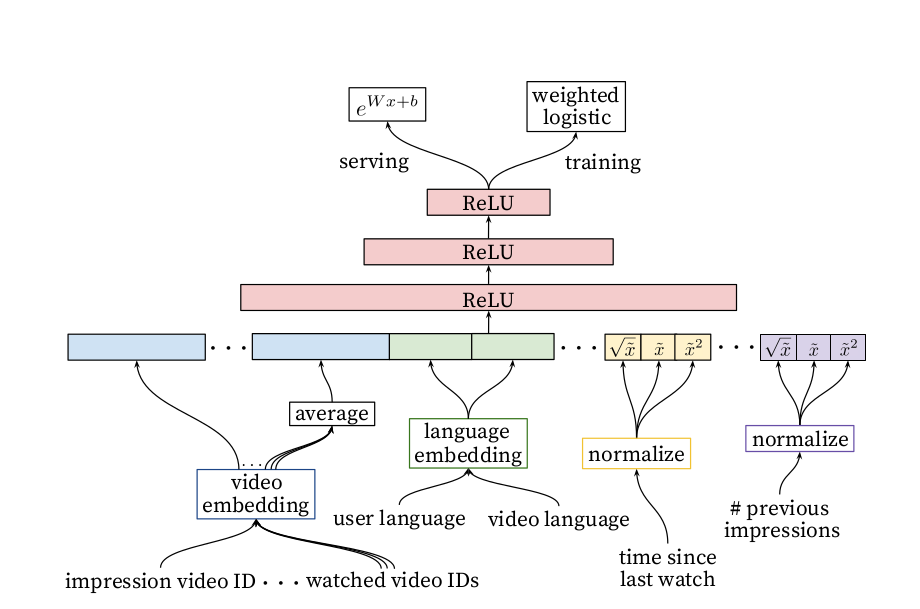
Fig.4 Ranking Model
Training:
Goal is to predict expected watch time given training examples that are either positive (content was clicked) or negative (content was not clicked). Positive examples are annotated with the amount of time the user spent watching the video. The model is trained with weighted logistic regression on the last layer which predict the expected watch time of the user and the model can be trained on both positive / negative data points i.e., watched and not watched content.
Model Structure:
The model structure is quite similar to the candidate generation model structure that we discussed in the previous post.
-
Input: All the above discussed input features.
-
Hidden Layers: Neural network of depth 4 is used 2048 –> 1024 —> 512 —> 256 all with ReLU activation function. You can further decrease or increase the no. of hidden layer based on hyperparameter tuning results. Following table is the you tube’s ranking model hidden layer experiment result.
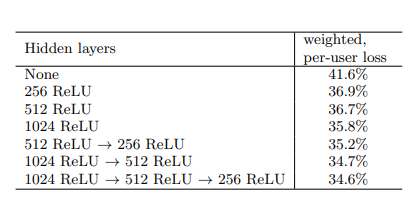
Fig.5 Hidden Layer Experiments
- Output Layer: Score for each provided candidates in the input
Serving:
Given N candidates based on their feature model will try to predict the expected watch time on each candidates and we can use this scores to rank these candidates and serve to the final user.